
MySQL多表查询

MySQL多表查询
28.7的博客MySQL 多表查询:原理、语法与实践
MySQL 多表查询是数据库核心操作之一,用于从多个关联表中联合提取数据。在实际业务中,数据通常不会集中在单张表(单表过大将导致查询效率急剧下降、维护困难),而是按业务逻辑拆分到不同表中(如用户表、文章表、标签表),多表查询正是实现数据关联整合的关键技术。
一、准备测试数据表
以下是本次演示使用的 3 张核心表,均与“用户-文章-标签”业务场景相关,表结构及数据通过截图展示:
| 表名 | 表作用 | 核心关联字段 |
|---|---|---|
tp_user_article |
存储文章基本信息 | user_id(关联用户表)、article_id(关联标签表) |
tp_users |
存储用户基本信息 | id(用户唯一标识,关联文章表的user_id) |
tp_article_tags |
存储文章的标签信息 | article_id(关联文章表) |
1.1 文章表(tp_user_article)
包含文章标题、内容、发布时间、作者ID等信息: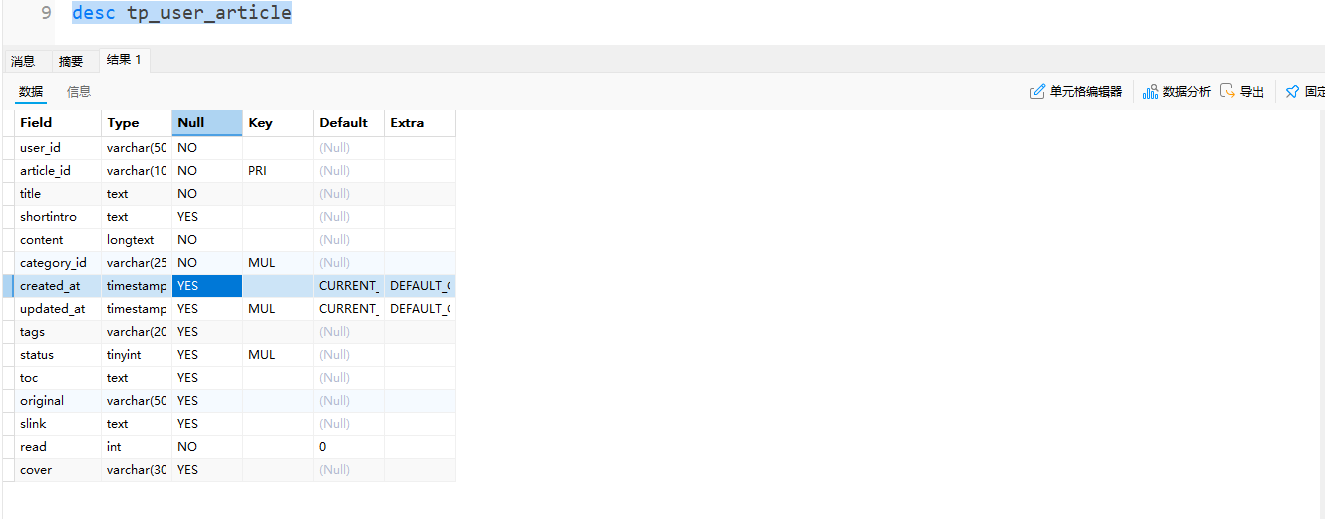
1.2 用户表(tp_users)
包含用户ID、用户名、头像、角色等信息: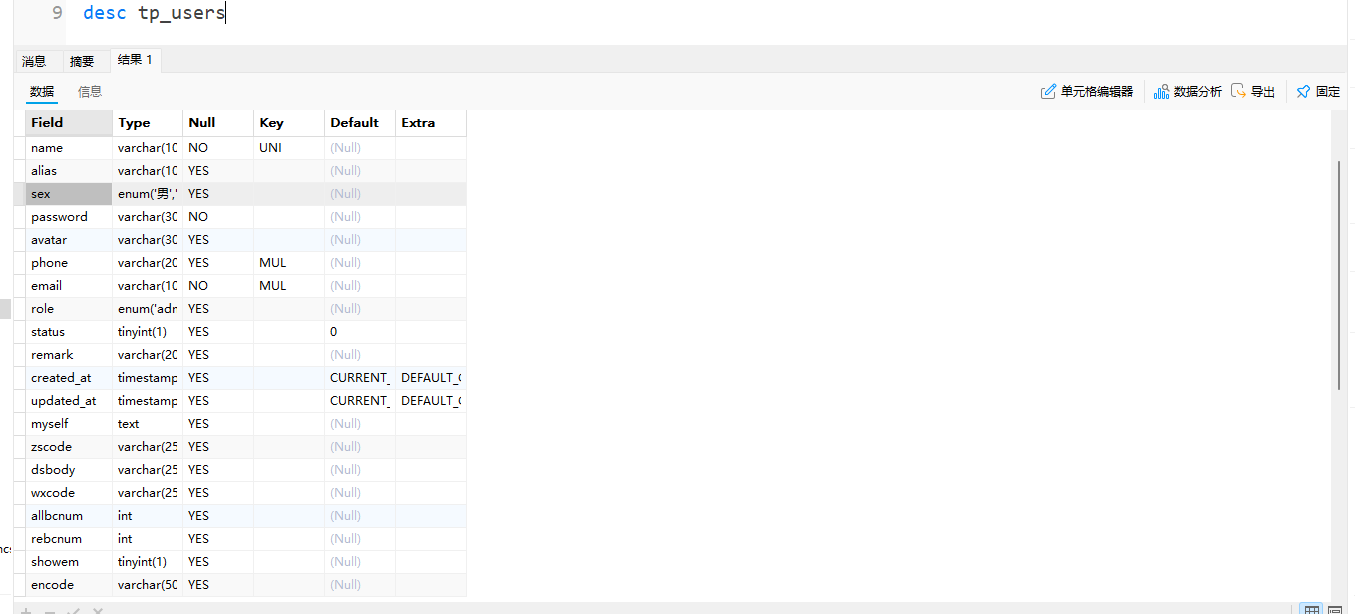
1.3 文章标签表(tp_article_tags)
包含文章ID、标签1、标签2、标签3等信息: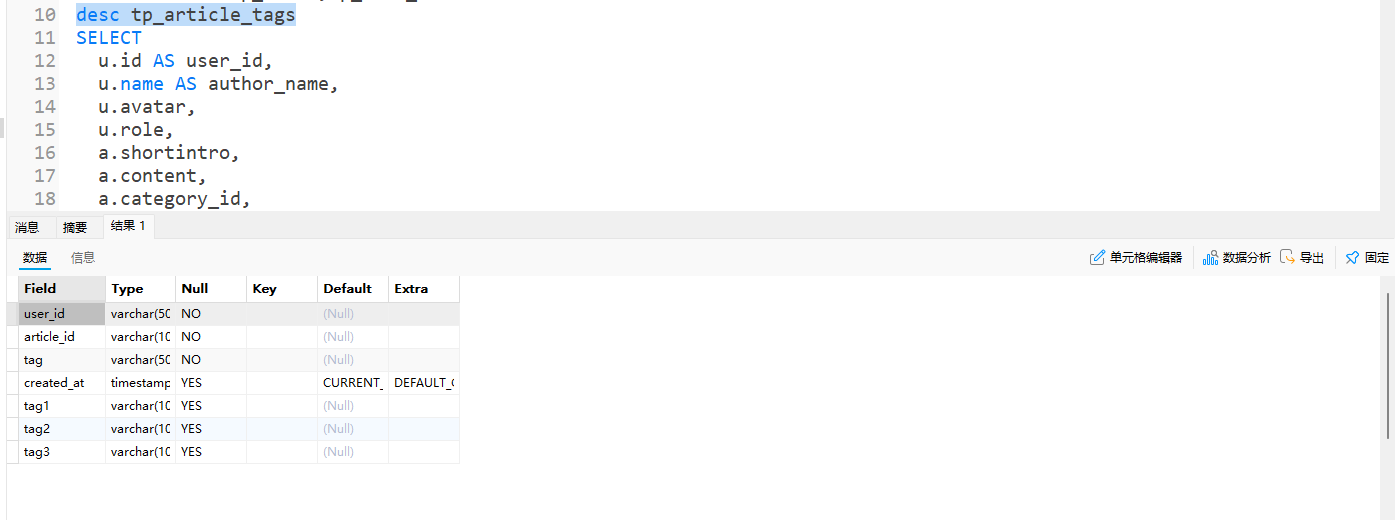
二、多表查询的核心方式
1. 交叉连接(CROSS JOIN):笛卡尔积(不推荐)
交叉连接会返回两个表所有记录的笛卡尔积,即左表的每一行与右表的每一行强制组合,结果行数 = 左表行数 × 右表行数。由于会产生大量冗余数据,且性能极差,实际业务中几乎不直接使用。
1.1 基础语法
1 | SELECT * FROM 表1 CROSS JOIN 表2; |
1.2 问题演示
对tp_users(15行)和tp_user_article(36行)执行交叉连接,结果行数 = 15 × 36 = 540 行(原文档显示570行为数据差异),查询耗时27秒,且包含大量无意义的“用户-文章”组合: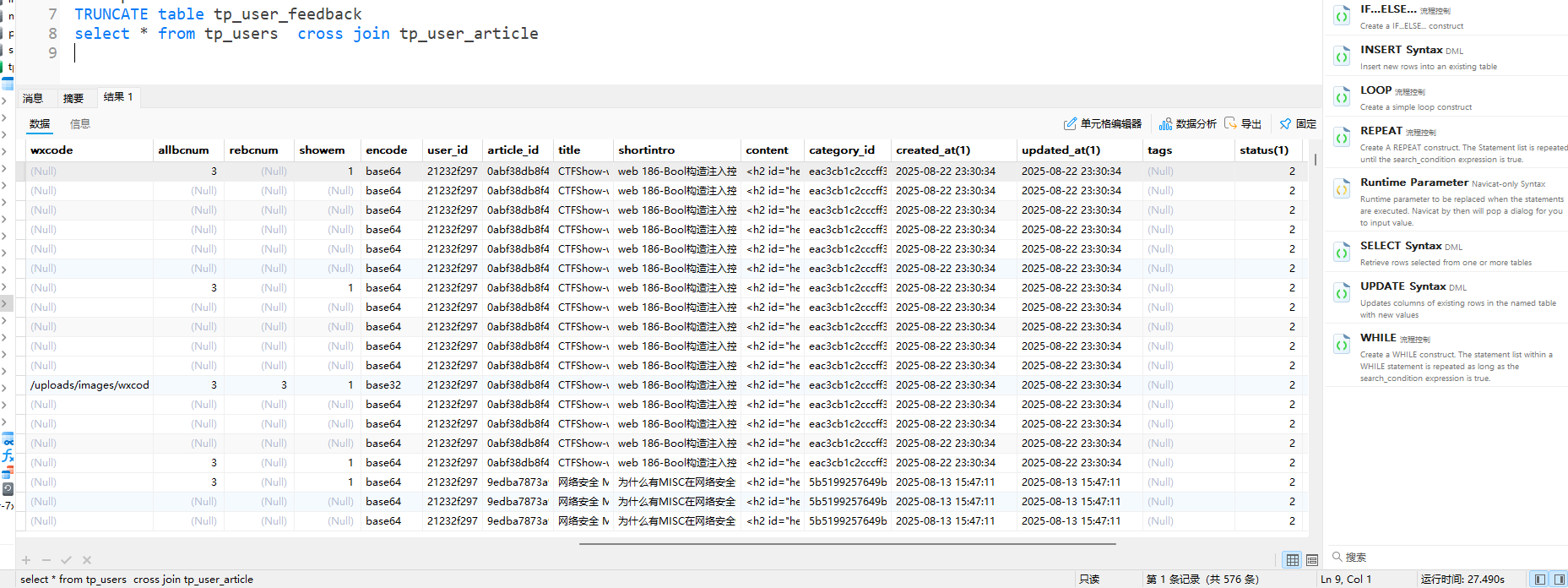
1.3 用 WHERE 过滤冗余记录
交叉连接的唯一价值是通过WHERE子句筛选出有效关联数据(本质是“伪内连接”),语法有两种等价形式:
形式1:显式 CROSS JOIN + WHERE
1 | SELECT 列名 |
示例:查询ID为21232f297a57a5a743894a0e4a801fc3的用户所发表的所有文章:
1 | SELECT * |
结果:返回36条有效数据,查询耗时2秒。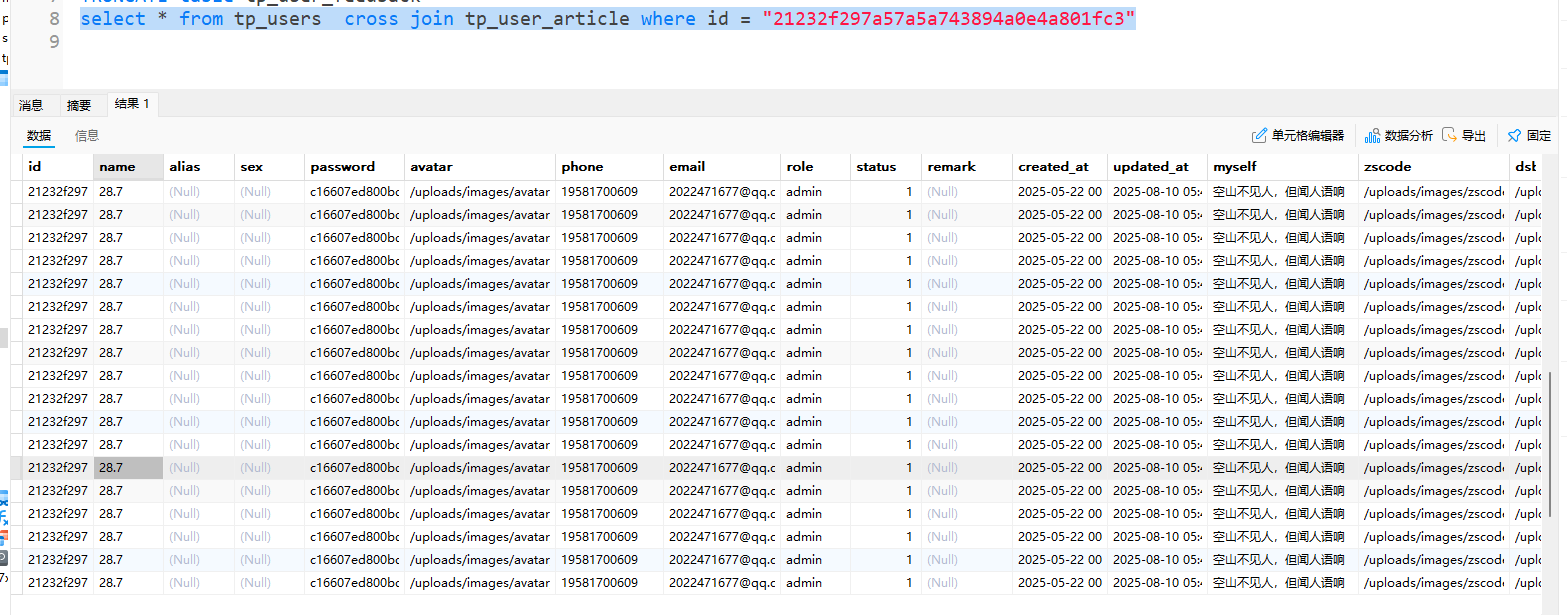
形式2:逗号分隔表(隐式交叉连接)
用逗号分隔表名的写法本质与CROSS JOIN等价,性能无差异,仅语法风格不同:
1 | SELECT 列名 |
2. 内连接(INNER JOIN):匹配关联记录(最常用)
内连接是实际业务中最常用的多表查询方式,仅返回两个表中满足关联条件的记录(即“交集”),不包含任何一方无匹配的数据。
2.1 基础语法
1 | SELECT 列名 |
注意:
INNER JOIN可省略INNER,直接写JOIN,语法等价。
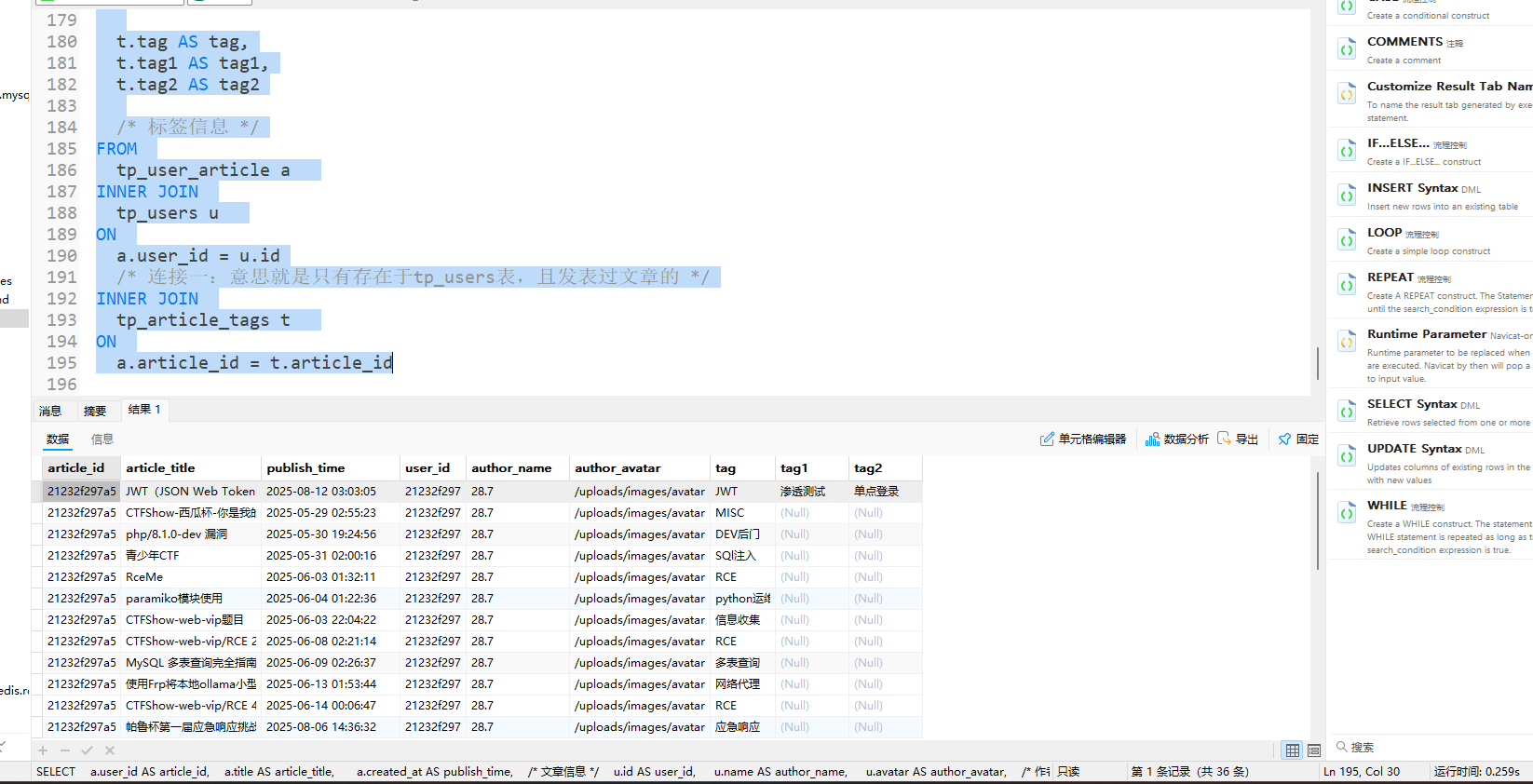
2.2 实践示例:查询“有作者+有标签”的文章
需求:提取所有文章的基本信息、作者信息(需存在于用户表)、标签信息(需存在于标签表),即“三者关联的有效数据”。
1 | SELECT |
2.3 查询结果
- 数据量:36条(仅包含“有作者且有标签”的文章)
- 耗时:1秒(效率优于交叉连接)
- 结果截图:

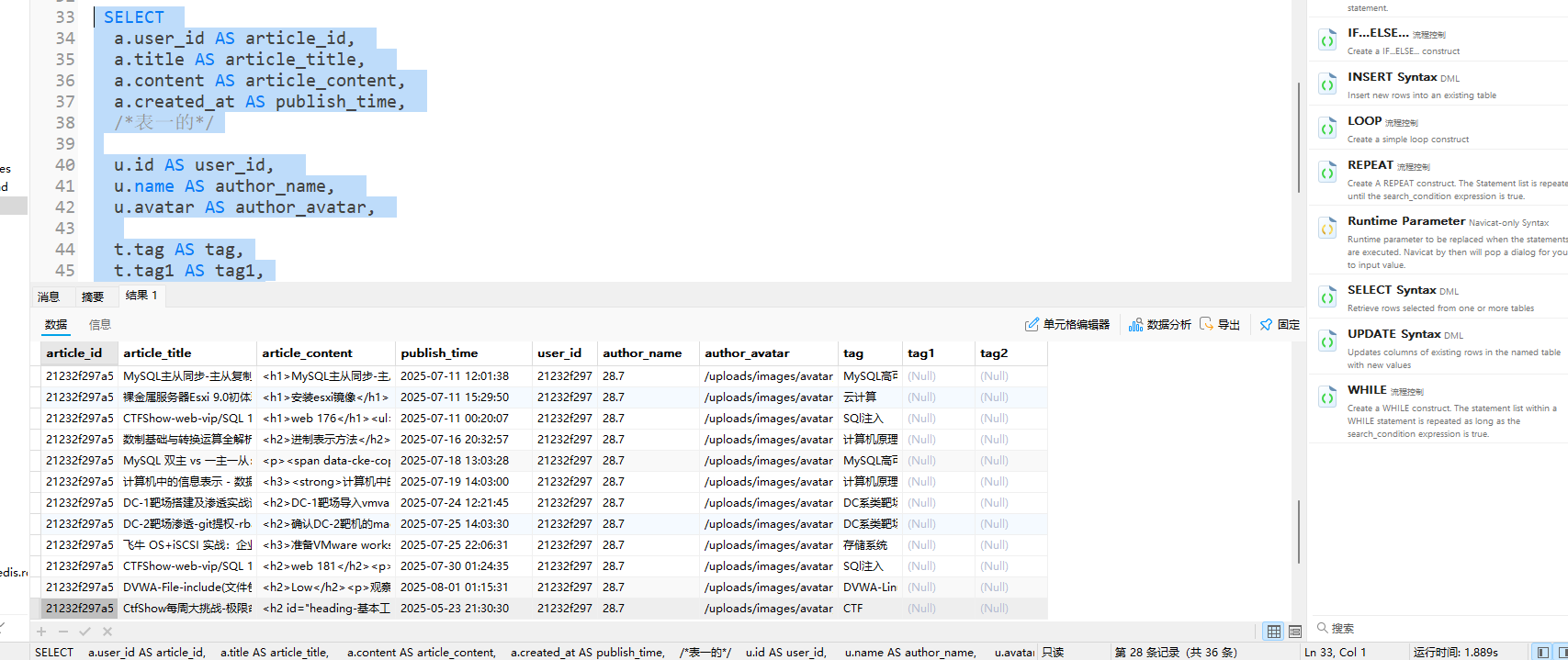
3. 外连接:保留未匹配的记录
外连接的核心是保留某一张表的所有记录,另一张表仅返回匹配的记录;未匹配的字段将填充为NULL。根据“保留表”的不同,分为左外连接和右外连接。
3.1 左外连接(LEFT JOIN / LEFT OUTER JOIN)
规则:保留左表的所有记录,右表仅返回与左表匹配的记录;右表无匹配时,字段值为NULL。
语法
1 | SELECT 列名 |
实践场景1:管理所有用户及其实发表的文章
需求:展示所有用户(包括未发表文章的用户),并关联其已发表的文章;未发表文章的用户,文章相关字段为NULL。
1 | SELECT |
结果:
- 数据量:51条(15个用户 + 36篇文章,其中15-(36篇文章对应的用户数)= 未发表文章的用户)
- 耗时:2秒
- 截图:未发表文章的用户,文章字段为
NULL
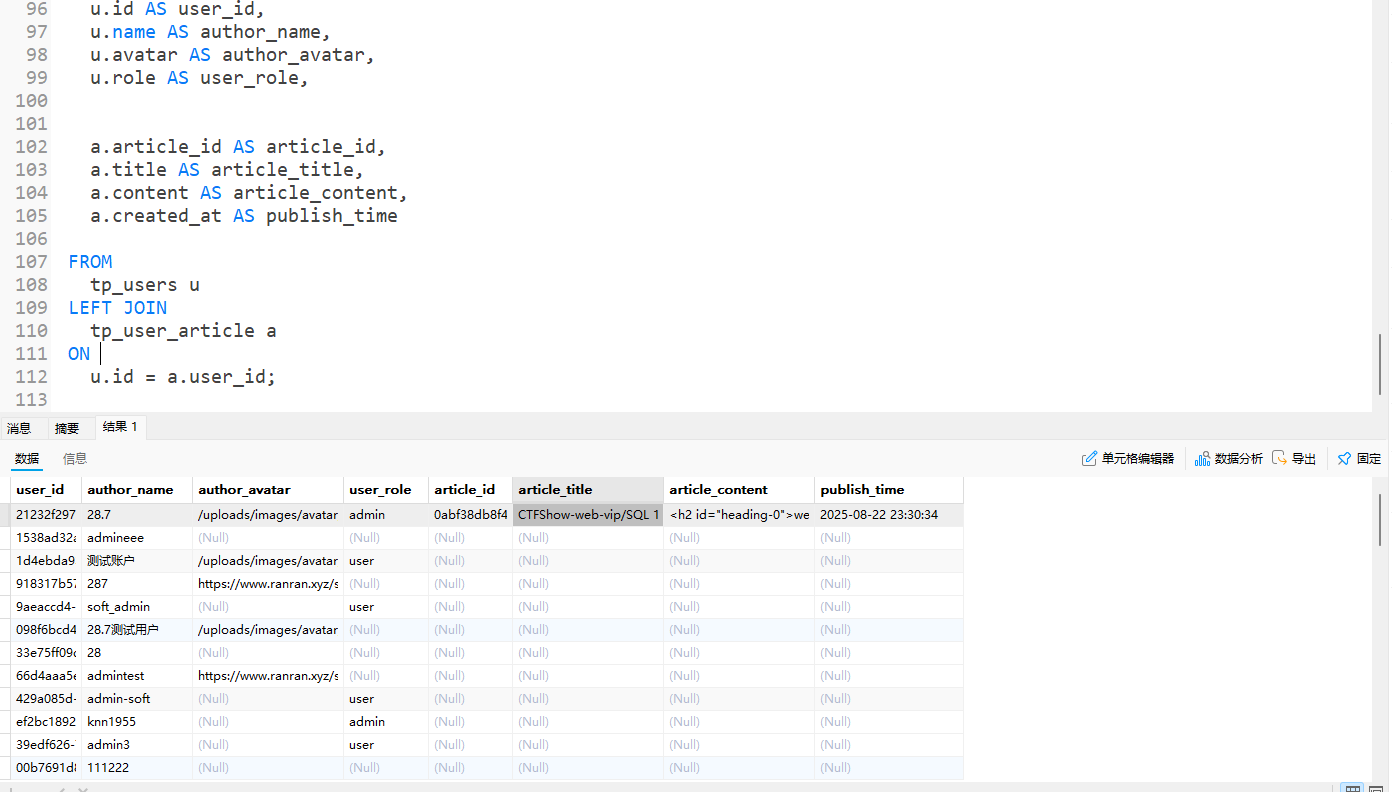
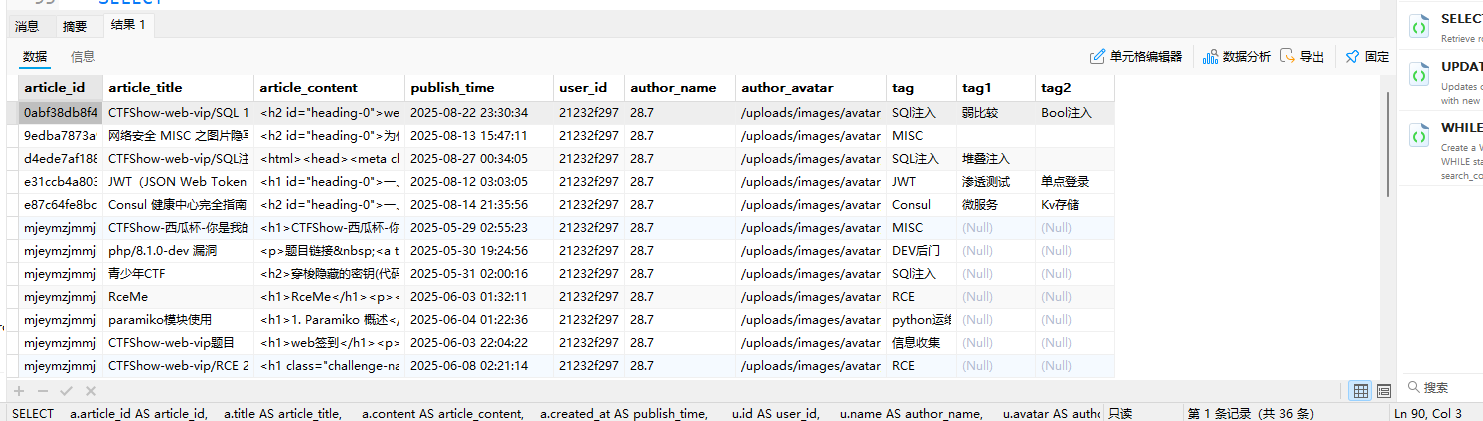
实践场景2:查询所有文章及标签(含无标签文章)
需求:展示所有文章(包括无标签的文章),关联其标签;无标签的文章,标签字段为NULL。
1 | SELECT |
结果:
- 数据量:36条(所有文章)
- 耗时:2秒
- 截图:无标签的文章,标签字段为
NULL
3.2 右外连接(RIGHT JOIN / RIGHT OUTER JOIN)
规则:保留右表的所有记录,左表仅返回与右表匹配的记录;左表无匹配时,字段值为NULL。
语法
1 | SELECT 列名 |
实践示例:用右外连接实现“保留所有用户”
需求与“3.1 场景1”一致(展示所有用户及文章),但用右外连接实现(将“需保留的表”放在RIGHT JOIN右侧)。
1 | SELECT |
结果:与左外连接场景1完全一致(未发表文章的用户,文章字段为NULL):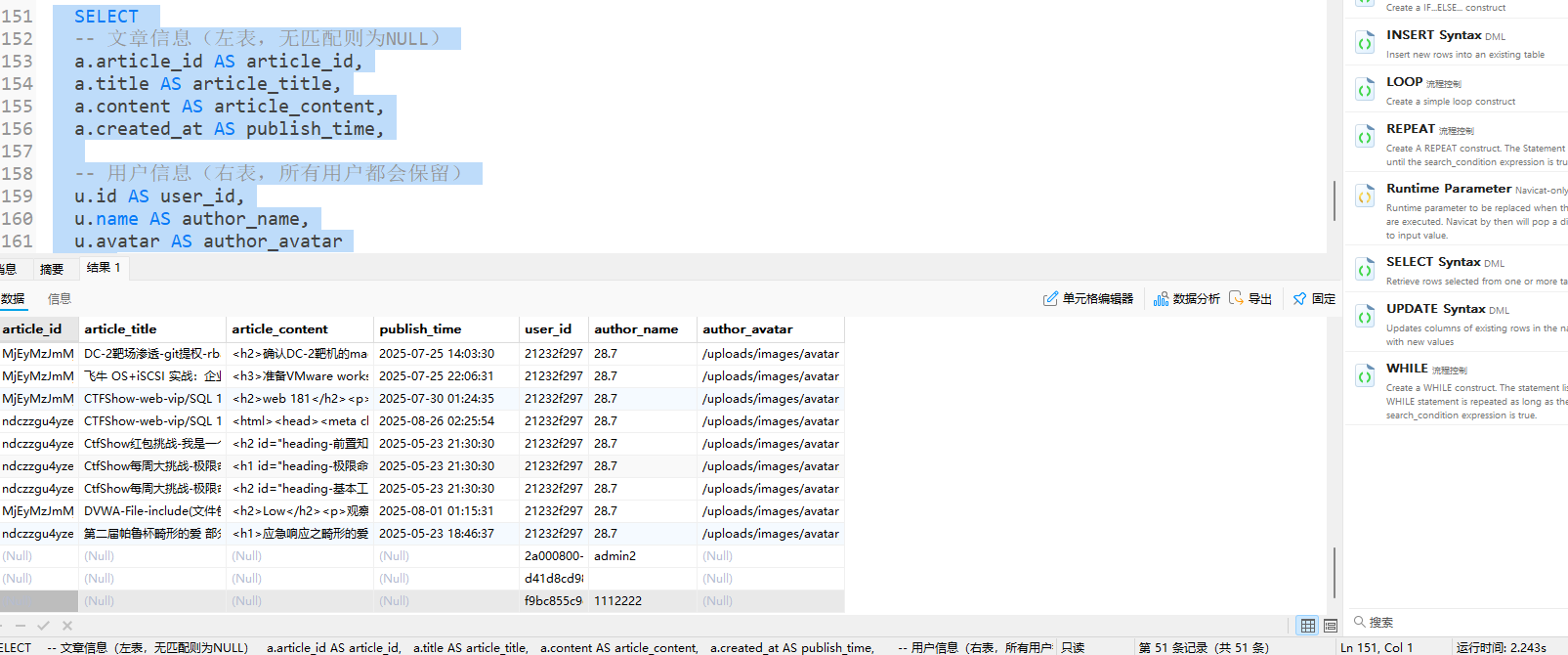
3.3 外连接小结
左外连接与右外连接的逻辑可完全等价,核心是“确定需要完整保留的表”:
- 若需保留表A → 表A作为左表,用
LEFT JOIN关联其他表; - 若需保留表B → 表B作为右表,用
RIGHT JOIN关联其他表。
三、多表查询优化:减少不必要字段
多表查询的性能瓶颈常源于“查询无关字段”,尤其是大字段(如LONGTEXT、BLOB)。以下通过实际案例演示优化思路。
3.1 优化前的问题
在“2.2 内连接三表查询”中,原SQL包含a.content(文章内容,LONGTEXT类型,单条数据可能上万字),但实际业务中(如文章列表页)无需展示完整内容,仅需标题、作者、标签等信息。
优化前SQL(含content字段):
1 | SELECT |
优化前性能:耗时1秒。
3.2 优化后的SQL(删除冗余字段)
删除a.content字段,仅保留业务所需的核心字段:
1 | SELECT |
3.3 优化效果
- 耗时从1秒缩短至0.2秒(性能提升80%);
- 数据传输量大幅减少(避免加载
LONGTEXT大字段)。
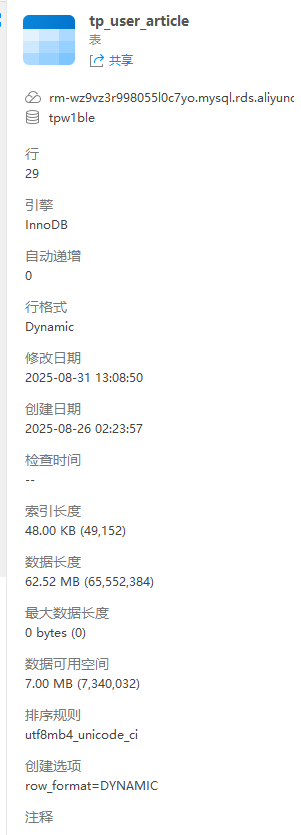
3.4 测试环境参考
本次测试使用阿里云原生MySQL实例,配置如下(供性能对比参考):
- 规格:10M带宽、4核CPU、4G内存;
- 文章表(
tp_user_article)数据量:36条(含LONGTEXT字段)。
四、核心总结
- 交叉连接:仅用于理解笛卡尔积,实际需配合
WHERE过滤,建议用内连接替代; - 内连接:最常用,返回表间交集,用
ON指定关联条件; - 外连接:保留某一张表的所有记录,左连保左表、右连保右表;
- 优化关键:避免查询无关字段(尤其是大字段),减少数据传输量,提升查询效率。










